为正确的工作选择正确的SQL引擎 在线数据处理与交易处理业务的优化之道
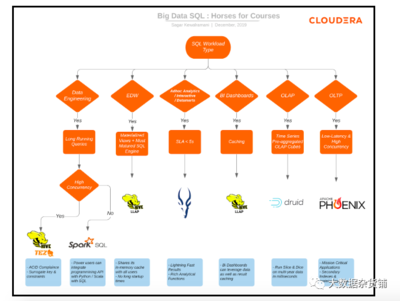
在当今数据驱动的商业环境中,无论是实时在线交易处理(OLTP)还是复杂的数据分析(OLAP),选择合适的SQL引擎都是确保系统高效、稳定运行的关键。特别是对于同时涉及在线数据处理与交易处理的业务,这一选择更显得至关重要。本文将探讨如何根据不同的业务需求,为正确的工作选择正确的SQL引擎。
理解业务场景:OLTP与OLAP的核心差异
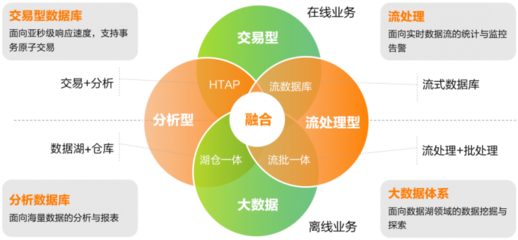
明确业务场景是选择SQL引擎的第一步。在线交易处理(OLTP)系统通常处理高并发的短事务,如电商订单、银行转账等,强调数据的快速插入、更新和查询,要求高可用性、强一致性和低延迟。而在线分析处理(OLAP)系统则侧重于复杂查询和大规模数据聚合,用于商业智能和数据分析,注重吞吐量和查询性能,对数据一致性要求相对宽松。许多现代业务(如金融科技、实时推荐系统)往往同时需要两者,这便引入了混合事务/分析处理(HTAP)的需求。
关键考量因素:性能、扩展性与成本
选择SQL引擎时,需综合评估以下因素:
- 性能指标:对于OLTP,关注每秒事务处理量(TPS)和延迟;对于OLAP,则看重查询响应时间和并发处理能力。引擎的优化器、索引支持和存储引擎设计直接影响这些指标。
- 扩展性:业务增长时,引擎是否支持水平扩展(如分片、分布式架构)至关重要。OLTP系统可能需要通过主从复制或集群来提升读写能力,而OLAP系统则依赖分布式计算框架(如Apache Spark集成)来处理海量数据。
- 数据一致性与隔离级别:OLTP业务通常需要ACID(原子性、一致性、隔离性、持久性)保证,因此应选择支持强事务的引擎(如MySQL、PostgreSQL)。OLAP场景可能放宽一致性要求,以换取更高性能,可考虑最终一致性引擎或数据仓库方案。
- 生态系统与集成:引擎是否与现有技术栈兼容?例如,云原生业务可能偏好与Kubernetes集成的引擎,而大数据平台则需兼容Hadoop或数据湖工具。
- 成本效益:包括许可费用、运维复杂度和云服务定价。开源引擎(如PostgreSQL、ClickHouse)可降低初始成本,但需自建运维能力;托管服务(如Amazon Aurora、Google BigQuery)简化管理,但长期使用成本较高。
主流SQL引擎推荐与适用场景
- OLTP场景:
- MySQL:广泛用于Web应用,具备良好的事务支持和社区生态,适合中小型交易系统。
- PostgreSQL:功能丰富,支持高级SQL特性(如JSONB、窗口函数),适合复杂事务和高数据完整性要求的业务。
- Amazon Aurora:云原生数据库,兼容MySQL/PostgreSQL,提供高可用和自动扩展,适合云上OLTP负载。
- OLAP场景:
- ClickHouse:列式存储引擎,专为实时分析设计,查询速度极快,适合日志分析和实时报表。
- Apache Druid:面向时序数据和事件流的高性能OLAP引擎,适用于监控和交互式查询。
- Snowflake或Google BigQuery:完全托管的云数据仓库,弹性伸缩,适合大规模数据分析,无需管理基础设施。
- HTAP混合场景:
- TiDB:开源分布式数据库,通过Raft协议保证强一致性,同时支持实时分析和事务处理,适合增长快速的互联网业务。
- CockroachDB:全球分布式数据库,提供ACID事务和水平扩展,适用于跨地域的OLTP和轻量OLAP。
- Oracle Database:企业级解决方案,内置OLAP功能(如内存列存储),但成本较高,适合大型传统企业。
实践策略:从评估到部署
- 需求分析:明确业务峰值负载、数据规模、查询模式(点查询vs.聚合查询)和SLA要求。可通过压力测试和原型验证来收集数据。
- 技术验证:在测试环境中部署候选引擎,模拟真实场景,评估性能指标和稳定性。关注引擎在故障恢复、备份和监控方面的表现。
- 架构设计:对于混合业务,可考虑解耦架构:使用OLTP引擎处理交易,通过ETL管道将数据同步到OLAP引擎进行分析。或直接采用HTAP引擎简化架构,但需权衡复杂度。
- 持续优化:选择后,通过索引优化、查询重写和资源调优来提升效率。随着业务演变,定期重新评估引擎是否仍是最佳选择。
###
为在线数据处理与交易处理业务选择SQL引擎,没有“一刀切”的方案。关键在于深入理解自身业务特点,平衡性能、一致性与成本。在快速迭代的数字时代,灵活可扩展的引擎往往更能适应未来变化。无论是传统关系型数据库还是新兴分布式系统,唯有将技术选型与业务目标对齐,才能构建出稳健高效的数据处理基石,驱动业务持续增长。
如若转载,请注明出处:http://www.xhltrade.com/product/26.html
更新时间:2026-04-19 11:51:34